1 Introduction
National Statistical Institutes (NSIs) publish a wide range of trusted, high quality statistical outputs. To achieve their objective of supplying society with rich statistical information these outputs are as detailed as possible. However, this objective conflicts with the obligation NSIs have to protect the confidentiality of the information provided by the respondents. Statistical Disclosure Control (SDC) or Statistical Disclosure Limitation (SDL) seeks to protect statistical data in such a way that they can be released without giving away confidential information that can be linked to specific individuals or entities.
In addition to official statistics there are several other areas of application of SDC techniques, including:
- Health information. This is one of the most sensitive areas regarding privacy.
- E-commerce. Electronic commerce results in the automated collection of large amounts of consumer data. This wealth of information is very useful to companies, which are often interested in sharing it with their subsidiaries or partners. Such consumer information transfer is subject to strict regulations.
This handbook aims to provide technical guidance on statistical disclosure control for NSIs on how to approach this problem of balancing the need to provide users with statistical outputs and the need to protect the confidentiality of respondents. Statistical disclosure control should be combined with other tools (administrative, legal, IT) in order to define a proper data dissemination strategy based on a risk management approach.
A data dissemination strategy offers many different statistical outputs covering a range of different topics for many types of users. Different outputs require different approaches to SDC and different mixture of tools.
Tabular data protection
Tabular data protection is the oldest and best established part of SDC, because tabular data have been the traditional output of NSIs. The goal here is to publish static aggregate information, i.e. tables, in such a way that no confidential information on specific individuals among those to which the table refers can be inferred. In the majority of cases confidentiality protection is achieved only by statistical tools due to the absence of legal and IT restrictions.
Dynamic databases
The scenario here is a database to which the user can submit statistical queries (sums, averages etc.). The aggregate information obtained as a result of successive queries should not allow him to infer information on specific individuals. The mixture of tools here may vary according to the setting and the data provided.
Microdata protection
In recent years, with the widespread use of personal computers and the public demand for data, microdata (that is data sets containing for each respondent the scores on a number of variables) are being disseminated to users in universities, research institutes and interest groups (Unece, 2006). Microdata protection is the youngest subdiscipline and has experienced continuous evolution in the last years. If microdata are freely disseminated then statistical disclosure limitation methods will be very severe to protect confidentiality of respondents; if, on the other hand, legal restrictions are in place (such as Commission Regulation 831/2002, see section 2.3) a different amount of information may be released.
Protection of output of statistical analyses
The need to allow access to microdata has encouraged the creation of Microdata Laboratories (Safe Centres) in many NSI. Due to an IT protected environment, legal and administrative restrictions users may analyse detailed microdata. Checking the output of these analyses to avoid confidentiality breaches is another field which is developing in SDC research.
This handbook provides guidance on how to protect confidentiality for all of these types of output using statistical methods.
This first chapter provides a brief introduction to some of the key concepts and definitions involved with this field of work as well as a high level overview of how to approach problems associated with confidentiality.
1.1 Concepts and Definitions
Disclosure
A disclosure occurs when a person or organisation recognises or learns something that they did not know already about another person or organisation, via released data. There are two types of disclosure risk; identity disclosure and attribute disclosure.
Identity disclosure occurs with the association of a respondent’s identity with a disseminated data record containing confidential information. (Duncan, et al (2001)).
Attribute disclosure occurs with the association of either an attribute value in the disseminated data or an estimated attribute value based on the disseminated data with the respondent. (Duncan, et al (2001)).
Some NSIs may also be concerned with the perception of disclosure risk. For example if small values appear in tabular output users may perceive that no (or insufficient) protection has been applied. More emphasis has been placed on this type of disclosure risk in recent years because of declining response rates and decreasing data quality.
Statistical disclosure control
Statistical disclosure control (SDC) techniques can be defined as the set of methods to reduce the risk of disclosing information on individuals, businesses or other organisations. SDC methods minimise the risk of disclosure to an acceptable level while releasing as much information as possible. There are two types of SDC methods; perturbative and non-perturbative methods.
Perturbative methods falsify the data before publication by introducing an element of error purposely for confidentiality reasons. Non-perturbative methods reduce the amount of information released by suppression or aggregation of data.
A wide range of different SDC methods are available for different types of outputs. There are two types of tabular output; magnitude and frequency tables.
Magnitude table
In a magnitude table each cell value represents the sum of a particular response, across all respondents that belong to that cell. Magnitude tables are commonly used for business or economic data providing, for example, turnover of all businesses of a particular industry within a region.
Frequency table
In a frequency table each cell value represents the number of respondents that fall into that cell. Frequency tables are commonly used for Census or social data providing, for example the number of individuals within a region who are unemployed.
Microdata
Microdata, or unit record data, is the form from which all other data outputs are derived and is the primary form that data is stored in. While in the past NSIs simply derived outputs of other forms, more and more, microdata is becoming a key output by itself.
Risk and Utility
NSIs should aim to determine optimal SDC methods and solutions that minimize disclosure risk while maximizing the utility of the data. Figure 1.1 contains an R-U confidentiality map developed by Duncan, et. al. (2001) where R is a quantitative measure of disclosure risk and U is a quantitative measure of data utility.
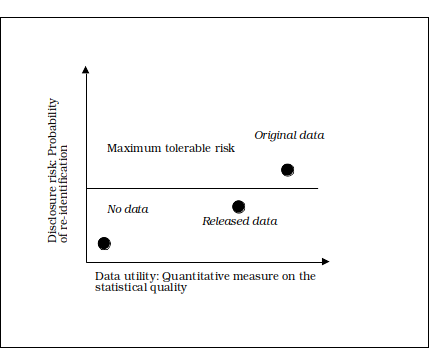
In the lower left hand quadrant of the graph low disclosure risk is achieved but also low utility, where no data is released at all. In the upper right hand quadrant of the graph high disclosure risk is realised but also high utility, represented by the point where the original data is released. The NSI must set the maximum tolerable disclosure risk based on standards, policies and guidelines. The goal in this disclosure risk–data utility decision problem is to then find the balance in maintaining the utility of the data but reducing the risk below the maximum tolerable threshold.
1.2 An approach to Statistical Disclosure Control
This section describes the approach that a data provider within an NSI should take in order to meet data users’ needs while managing confidentiality risks. A general framework for addressing the question of confidentiality protection for different statistical outputs is proposed based on the following five key stages and we outline how the handbook provides guidance on the different aspects of this process.
- Why is confidentiality protection needed?
- What are the key characteristics and uses of the data?
- What disclosure risks need to be protected against?
- Disclosure control methods
- Implementation
Why is confidentiality protection needed?
There are three main reasons why confidentiality protection is needed for statistical outputs.
- It is a fundamental principle for Official Statistics that the statistical records of individual persons, businesses or events used to produce Official Statistics are strictly confidential, and are to be used only for statistical purposes. Principle 6 of the UN Economic Commission report 'Fundamental Principles for Official Statistics', April 1992 states:
'Individual data collected by statistical agencies for statistical compilation, whether they refer to natural or legal persons, are to be strictly confidential and used exclusively for statistical purposes'. The disclosure control methods applied for the outputs from an NSI should meet the requirements of this principle. - There may be legislation that places a legal obligation on an NSI to protect individual business and personal data. In addition where public statements are made about the protection of confidentiality or pledges are made to respondents of business or social surveys these place a duty of confidence on the NSI that the NSI must legally comply with.
- One of the reasons why the data collected by NSIs is of such high quality is that data suppliers or respondents have confidence and trust in the NSI to preserve the confidentiality of individual information. It is essential that this confidence and trust is maintained and that identifiable information is held securely, only used for statistical purposes and not revealed in published outputs.
More information on regulations and legislation is provided in Chapter 2.
What are the key characteristics and uses of the data?
When considering confidentiality protection of a statistical output it is important to understand the key characteristics of the data since all of these factors influence both disclosure risks and appropriate disclosure control methods. This includes knowing the type of data, e.g. full population or sample survey; sample design, an assessment of quality e.g. the level of non-response and coverage of the data; variables and whether they are categorical or continuous; type of outputs, e.g. microdata, magnitude or frequency tables. Producers of statistics should design publications according to the needs of users, as a first priority. It is therefore vital to identify the main users of the statistics, and understand why they need the figures and how they will use them. This is necessary to ensure that the design of the output is relevant and the amount of disclosure protection used has the least possible adverse impact on the usefulness of the statistics. Section 3.2 addresses some examples on how to carry out this initial analysis.
What disclosure risks need to be protected against?
Disclosure risk assessment then combines the understanding gained above with a method to identify situations where there is a likelihood of disclosure. Risk is a function of likelihood (related to the design of the output), and impact of disclosure (related to the nature of the underlying data). In order to be explicit about the disclosure risks to be managed one should consider a range of potentially disclosive situations or scenarios and take action to prevent them. A disclosure scenario describes (i) which information is potentially available to an ‘intruder’ and (ii) how the intruder would use the information to identify an individual. A range of intruder scenarios should be determined for different outputs to provide an explicit statement of what the disclosure risks are, and what elements of the output pose an unacceptable risk of disclosure. Issues in developing disclosure scenarios are provided in Section 3.3.2. Risk assessment methods for microdata are covered in Section 3.3 and different rules applied to assess the risk of magnitude and frequency tables are described in Chapter 4 and 5 respectively.
Disclosure control methods
Once an assessment of risk has been undertaken an NSI must then take steps to manage any identified risks. The risk within the data is not entirely eliminated but is reduced to an acceptable level, this can be achieved either through the application of statistical disclosure control methods or through the controlled use of outputs, or through a combination of both. Several factors must be balanced through the choice of approach. Some measure of information loss and impact on main uses of the data can be used to compare alternatives. Any method must be implemented within a given production system so available software and efficiency within demanding production timetables must be considered. Statistical disclosure control methods used to reduce the risk of microdata, magnitude tables and frequency tables are covered in Chapter 3, 4 and 5 respectively. Chapter 6 provides information on how disclosure risk can be managed by restricting access.
Implementation
The final stage in this approach to a disclosure control problem is implementation of the methods and dissemination of the statistics. This will include identification of the software to be used along with any options and parameters. The proposed guidance will allow data providers to set disclosure control rules and select appropriate disclosure control methods to protect different types of outputs. The most important consideration is maintaining confidentiality but these decisions will also accommodate the need for clear, consistent and practical solutions that can be implemented within a reasonable time and using available resources. The methods used will balance the loss of information against the likelihood of individuals’ information being disclosed. Data providers should be open and transparent in this process and document their decisions and the whole risk assessment process so that these can be reviewed. Users should be aware that a dataset has been assessed for disclosure risk, and whether methods of protection have been applied. For quality purposes, users of a dataset should be provided with an indication of the nature and extent of any modification due to the application of disclosure control methods. Any technique(s) used may be specified, but the level of detail made available should not be sufficient to allow the user to recover disclosive data. Each chapter of the handbook provides details of software that can be used to assess and manage disclosure risk of the different statistical outputs.
1.3 The chapters of the handbook
This book starts with an overview of regulations describing the legal underpinning of Statistical Disclosure Control in Chapter 2. Microdata are covered in Chapter 3, magnitude tables are addressed in Chapter 4 and Chapter 5 provides guidance for frequency tables. Chapter 6 describes the confidentiality problems associated with microdata access issues. Within each section different approaches to assessing and managing disclosure risks are described and the advantages and disadvantages of different SDC methods are discussed. Where appropriate recommendations are made for best practice.
In Chapter 7 a glossary of statistical terms used in Statistical Disclosure Control has been included.
1.4 References
Duncan, G., Keller-McNulty, S., and Stokes, S. (2001) Disclosure Risk vs. Data Utility: the R-U Confidentiality Map, Technical Report LA-UR-01-6428, Statistical Sciences Group, Los Alamos, N.M.: Los Alamos National Laboratory
Trewin, D et al. (2007) Principles and Guidelines of Good Practice for Managing Statistical Confidentiality and Microdata Access, UNECE United Nations Economic commission for Europe: https://unece.org/fileadmin/DAM/stats/publications/Managing.statistical.confidentiality.and.microdata.access.pdf