Targeted Record Swapping
Johannes Gussenbauer
2023-08-30
Source:vignettes/recordSwapping.Rmd
recordSwapping.RmdOverview
This is the vignette for the R-Package recordSwapping, which can be used to apply the record swapping algorithm to a micro data set. The implementation of the procedure was done purely in C++ and is based on the SAS code on targeted record swapping from ONS. There are, however, substantial differences between the SAS and C++ Code. Some of these differences are the result of improving the run-time for the C++ implementation. In the next section, the differences between the 2 implementations are presented further. The R-Package is just as a front end to easily call the procedures and for testing purposes.
Functionality
The targeted record swapping can be applied with the function
recordSwap(). All other functions in the package are called
from inside recordSwap() and are only exported for testing
purposes. The function has the following arguments:
recordSwap(std::vector< std::vector<int> > data, int hid,
std::vector<int> hierarchy,
std::vector<std::vector<int>> similar,
double swaprate,
std::vector<std::vector<double>> risk, double risk_threshold,
int k_anonymity, std::vector<int> risk_variables,
std::vector<int> carry_along,
int &count_swapped_records,
int &count_swapped_hid,
std::string log_file_name,
int seed = 123456)- data micro data containing ONLY integer values, rectangular table format.
- hid column index in which refers to the household identifier.
- hierarchy column indices of variables in which refer to the geographic hierarchy in the micro data set. For instance county > municipality > district.
- similar vector of vector containing the similarity profiles that are sets of variables in which should be considered when swapping households. corresponds to the first set similarity variables, to the second set and so on.
- swaprate double between 0 and 1 defining the proportion of households which should be swapped, see details for more explanations
-
risk vector of vector containing the risk of each
individual for each hierarchy level.
risk[0]corresponds to the risks of the first record for all hierarchy levels,risk[1]for the second record and so on. Should be ignored, for now, it is not fully tested yet. - risk_threshold risk threshold, which determines if a record has to be swapped and over which hierarchy level. This overwrites k_anonymity. Should be ignored, for now, it is not fully tested yet.
-
k_anonymity integer defining the threshold of high
risk households (k-anonymity). A record is not at risk if
k_anonymity >= counts. -
risk_variables column indices of variables in which
will be considered for estimating the risk. This is only used if
riskwas not supplied. -
carry_along column indices of variables in which
are additionally swapped. These variables do not interfere with the
procedure of finding a record to swap with. This parameter is only used
at the end of the procedure when swapping the hierarchies. We note that
the variables to be used as
carry_alongshould be at household level. In case it is detected that they are at individual level (different values withinhid), a warning is given because unexpected results may occur since the first observed value within the Household for any variable is used for all members in the swapped household. - count_swapped_records, count_swapped_hid count number of households and records swapped
-
log_file_name path for writing a log file. The log
file contains a list of household IDs (
hid) that could not have been swapped and is only created if any such households exist. - seed integer defining the seed for the random number generator, for reproducibility.
IMPORTANT: The argument data contains
the micro data and can be understood as a vector of vectors. Inside the
function, data is expected to contain each column of the
input data as std::vector<int> which are then again
stored in an std::vector< std::vector<int> >.
So data[0] addresses variables of the first record and
data[0][0] the first column of the first record. The same
logic hold for the argument risk.
Some differences to SAS-Code
Risk definition
-
C++-Code: Risk is calculated using counts over the
geographic hierarchies (
hierarchy) and the combination of all risk variables. -
SAS-Code: Risk is calculated using counts for each
geographic hierarchy (
hierarchy) and risk variable separately. These risks are then combined to produce a single risk value for each record.
Sampling probability
- C++-Code: Sampling probability \(p_{y,h}\) for household \(y\) at the geographic hierarchy \(h\) is derived from the risks \(r_{i,h}\) of all individuals living in the same household. The risk \(r_{i,h}\) for each individual \(i\) in geographic hierarchy (\(h\)) is currently estimated through the k-anonymity rule. \(r_{i,h}\) is then defined as
\[ r_{i,h} = (\sum\limits_{j=1}^{N_{g_1}}1[v_{1(i)}=v_{1(j)} \land ... \land v_{p(i)}=v_{p(j)}])^{-1} \quad , \]
with \(v_1,\ldots,v_p\) as a set of risk variables, \(N_{g_1}\) as the number of persons living in region \(g_1\) and \(1[...]\) as the indicator function. \(1[v_{1(i)}=v_{1(j)} \land ... \land v_{p(i)}=v_{p(j)}]\) is 1 if individual \(j\) as the same values for risk variables \(v_1,\ldots,v_p\) as individual \(i\) and is 0 otherwise. Casually speaking
\[ r_{i,h} \sim \frac{1}{counts} \quad . \]
The sampling probability for household \(y\), \(p_{y,h}\) in hierarchy \(h\), is then defined by the maximum of risk across all household member
\[ p_{y,h} = \max_{i\text{ in household }y}(r_{i,h}) \quad . \] This sampling probability is used for selecting households for swapping as well as donor households.
- SAS-Code: Sampling probability is derived from multiple factors.
\[ p_i = \begin{cases} 0.999 \quad \text{for low risk household} \\ \frac{b\cdot N_{high}}{SA\cdot c-b\cdot c} \quad \text{for }b>0 \\ \frac{0.2\cdot N_{high}}{SA\cdot c-0.2\cdot c} \quad \text{for }b=0 \\ \frac{0.1\cdot N_{high}}{SA\cdot c-0.1\cdot c} \quad \text{for }b<0 \end{cases} \] where \[ b = SA - N_{high}\\ c = N_{netto} - N_{high} \] with \(SA\) as the sample size, \(N_{high}\) as the number of high risk households in the geographic area and \(N_{netto}\) the number of non-imputed records in the geographic area.
Swapping Records
-
C++-Code: Swaps are made in every hierarchy level
and records which do not fulfil the k-anonymity are swapped. The donor
set of records to be swapped with is always made out of every record
which does not belong to the same geographic area as the swapped
households. At the lowest hierarchy level, an additional number of
households is swapped such that the proportion of households swapped is
equal to the number in
swaprate. If the proportion of already swapped households succeeds these values then records that do not fulfil the k-anonymity are also swapped.
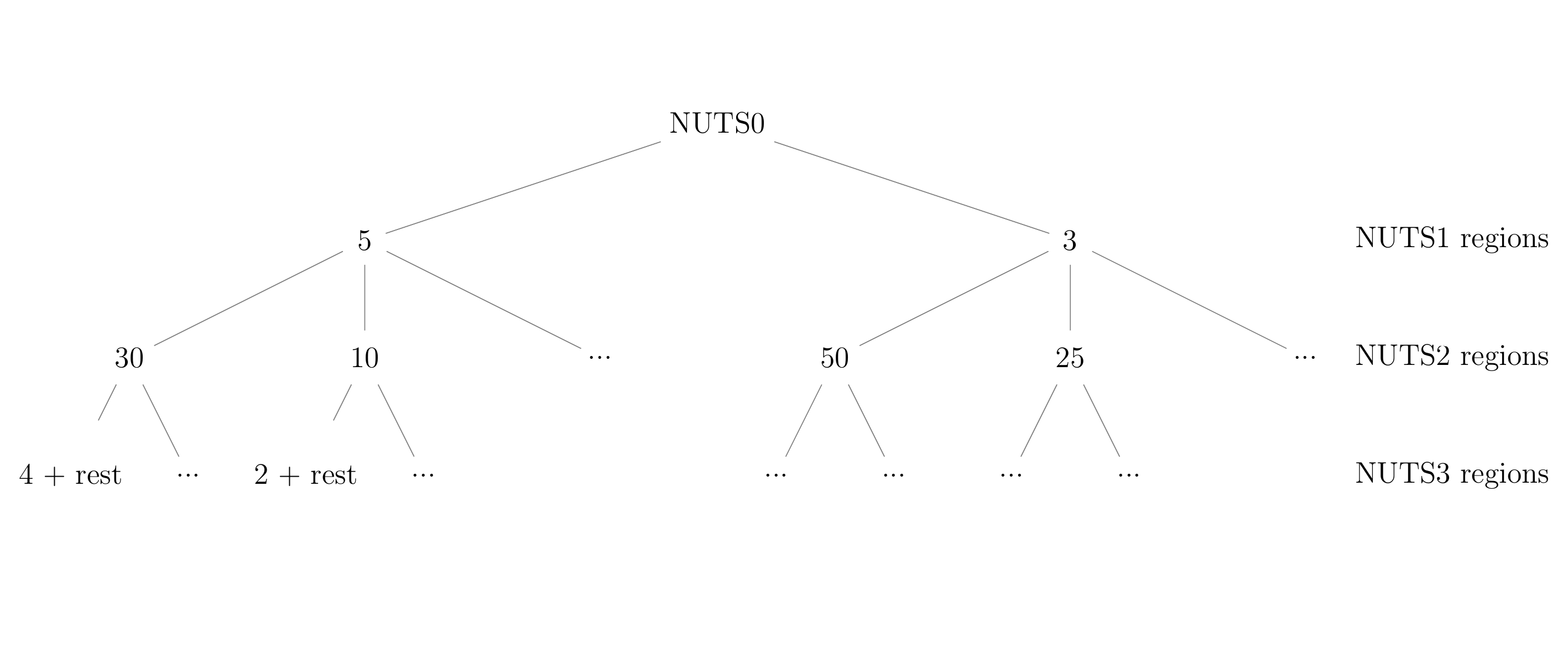
Figure 1 displays an example with hierarchy levels NUTS1 > NUTS2 > NUTTS3 where the numbers of high risk households are displayed at the end of the edges. For instance, in the first NUTS1 region, there are 5 high risk households that will be swapped with households from other NUTS1 regions. In the first NUTS2 region, there are 10 high risk households that will be swapped with households that are not in the same NUTS2 region. At the lowest level, the NUTS3 regions, the number of swaps, \(n_{swaps}\) for the first district is defined by
\[ n_{swaps} = 2 + Rest\\ Rest = \max(0,N\cdot s - n_{already}) \] with \(N\) as the number of households in the district, \(n_{already}\) as the number of already swapped households in the district and \(s\) as the swap rate.
- SAS-Code Swaps are made in every hierarchy level and depending on the sampling probability, high risk households are more likely to be swapped than low risk households, but they are not mandatorily swapped. The number of swappes in each hierarchy level is defined by the number of high risk records and the total number of records in the geographic area. For instance, having the geographic hierarchy county > municipality > district, the number of Swaps in the municipality \(m\) of county \(n\) is defined by
\[ SWAP_m = \frac{SIZE_m+RISK_m}{2} \] where \(SIZE_m\) can be derived by using the reciprocal number of households of each municipality in county \(n\).
\[ SIZE_m = \frac{N_m^{-1}}{\sum_iN_i^{-1}}\cdot sN_n \] with \(N_m\) as the number of households in municipality \(m\), \(s\) the global swaprate and \(N_n\) as the number of households in county \(n\). \(RISK_m\) can be derived using the proportion of high risk households in each municipality
\[ RISK_m = \frac{H_m}{\sum_iH_i}\cdot sN_n \]
with \(H_m\) as the proportion of high risk households in municipality \(m\).
Application
The package was tested on randomly generated data, which contained 5 geographic levels and some other sociodemographic variables.
## nuts1 nuts2 nuts3 lau2 hid hsize ageGroup gender national htype hincome
## 1: 1 11 1104 11041 1 5 4 2 4 4 5
## 2: 1 11 1104 11041 1 5 4 1 4 4 5
## 3: 1 11 1104 11041 1 5 2 1 2 4 5
## 4: 1 11 1104 11041 1 5 6 2 5 4 5
## 5: 1 11 1104 11041 1 5 2 1 1 4 5
## ---
## 349688: 2 23 2308 23085 100000 6 3 1 4 7 9
## 349689: 2 23 2308 23085 100000 6 5 1 2 7 9
## 349690: 2 23 2308 23085 100000 6 5 2 2 7 9
## 349691: 2 23 2308 23085 100000 6 3 1 2 7 9
## 349692: 2 23 2308 23085 100000 6 6 1 1 7 9Applying the record swapping to dat could look like this
hierarchy <- c("nuts1","nuts2")
risk_variables <- c("hincome","ageGroup","gender")
k_anonymity <- 3
swaprate <- .05
hid <- "hid"
similar <- "hsize"
dat_swapped <- recordSwap(data = dat, hid = hid,
hierarchy = hierarchy,
similar = similar,
risk_variables = risk_variables,
k_anonymity = k_anonymity,
swaprate = swaprate)## Recordswapping was successful!
dat_swappedHere the procedure was applied to dat
- using every hierarchy level,
nuts1andnuts2 - using
hsizeas the similarity variable (so only households with the same household size are swapped) - using
hIncome,ageGroup,genderas risk variables - setting the k-anonymity rule to 3
- setting the swaprate to 0.05
If k_anonymity <- 0 only the swaprate is considered.
Then at most th*100% of the households are swapped. If the
sample is very small, the actual number of swaps can be smaller,
however, this can only happen if some regions have a very small number
of households, e.g. 1,2,3,…
k_anonymity <- 0
swaprate <- .05
dat_swapped <- recordSwap(data = dat, hid = hid,
hierarchy = hierarchy,
similar = similar,
risk_variables = risk_variables,
k_anonymity = k_anonymity,
swaprate = swaprate)## Recordswapping was successful!
dat_swappedComparing number of swapped households
dat_compare <- merge(dat[,.(paste(nuts1[1],nuts2[1])),by=hid],
dat_swapped[,.(paste(nuts1[1],nuts2[1])),by=hid],by="hid")
# number of swapped households
nrow(dat_compare[V1.x!=V1.y])## [1] 5000
# swaprate times number of households in data
dat[,uniqueN(hid)]*swaprate## [1] 5000Supplying index vectors
Instead of column names, index vectors can be supplied for parameters
hid, hierarchy, similar and
risk_variables.
hierarchy <- c(1,2) # ~ c("nuts1","nuts2")
risk_variables <- c(11,7,8) # ~ c("hincome","ageGroup","gender")
hid <- 5 # ~ "hid"
similar <- 6 # ~ "hsize"
dat_swapped <- recordSwap(data = dat, hid = hid,
hierarchy = hierarchy,
similar = similar,
risk_variables = risk_variables,
k_anonymity = k_anonymity,
swaprate = swaprate)## Recordswapping was successful!Please note that the underlying c++-routines expect
indices starting from 0 but in R indices start with 1. The
wrapper function recordSwap() converts indices or column
names in R into the correct format for the c++
routines. So using column indices for this function call should be done
in the usually R-fashion where indices start with 1.
Similarity profiles
In some cases, the condition of finding a similar household
given by the parameter similarity might be too strict. And
thus, it is not possible to swap the necessary number of households due
to the lack of a suitable donor household.
# demonstrate on small data set
dat <- createDat(N=10000)
hierarchy <- c("nuts1","nuts2")
risk_variables <- "gender"
# similarity profile contains:
# nuts1 + hsize + htype + hincome
similar <- c("nuts1","hsize","htype","hincome")
# procedure will not always find a suitable donor
dat_swapped <- recordSwap(data = dat, hid = hid,
hierarchy = hierarchy,
similar = similar,
risk_variables = risk_variables,
k_anonymity = 3,
swaprate = 0.05,
seed = 123456L)## Donor household was not found in 2 case(s).
## See TRS_logfile.txt for a detailed listThe expected number of swapped households for a population of 10000 households and a swapping rate of 0.05 is 500. The actual number of swaps was however:
dat_compare <- merge(dat[,.(paste(nuts1[1],nuts2[1])),by=hid],
dat_swapped[,.(paste(nuts1[1],nuts2[1])),by=hid],by="hid")
# number of swapped households
nrow(dat_compare[V1.x!=V1.y])## [1] 496With the parameter similar multiple similarity profiles
can be defined, if the parameter input is a list. If a
donor could not be found for the first similarity profile
(similar[[1]]) then a donor is searched for using the next
similarity profile (similar[[2]]) and so on.
Using multiple similarity profiles makes it easy to supply fall-back profiles if the initial profile is too specific.
# additional profile contains only hsize
similar <- list(similar)
similar[[2]] <- "hsize"
similar## [[1]]
## [1] "nuts1" "hsize" "htype" "hincome"
##
## [[2]]
## [1] "hsize"
# procedure found donors for every record
dat_swapped <- recordSwap(data = dat, hid = hid,
hierarchy = hierarchy,
similar = similar,
risk_variables = risk_variables,
k_anonymity = 3,
swaprate = 0.05,
seed = 123456L)## Recordswapping was successful!
dat_compare <- merge(dat[,.(paste(nuts1[1],nuts2[1])),by=hid],
dat_swapped[,.(paste(nuts1[1],nuts2[1])),by=hid],by="hid")
# number of swapped households
nrow(dat_compare[V1.x!=V1.y])## [1] 500Carry along variables
Using the function recordSwap() like above always
results in swapping the variables defined through variable
hierarchy. Sometimes it might be useful to swap more
variables than the ones stated in hierarchy.
When we apply the record swapping using hierarchy-levels
nuts1 and nuts2 then the nuts3
and lau2-variable in our data set will stay unchanged. Thus
for the resulting data set, the variables nuts1 and
nuts2 are no longer coherent with nuts3 and
lau2.
Let’s have a more detailed look at the problem
hid <- "hid"
hierarchy <- c("nuts1","nuts2")
similar <- c("hsize")
risk_variables <- c("hincome","htype")
dat_swapped <- recordSwap(data = copy(dat),
hid = hid,
hierarchy = hierarchy,
similar = similar,
risk_variables = risk_variables,
swaprate = 0.05,
seed=1234L)## Recordswapping was successful!
# compare results
dat_compare <- merge(dat[,.(paste(nuts1[1],nuts2[1])),by=hid],
dat_swapped[,.(paste(nuts1[1],nuts2[1])),by=hid],by="hid")
head(dat_compare[V1.x!=V1.y])## hid V1.x V1.y
## 1: 1 3 35 2 21
## 2: 20 1 11 3 35
## 3: 37 1 11 2 24
## 4: 84 2 21 2 22
## 5: 85 3 31 1 13
## 6: 100 3 33 3 35For nuts1==1 and nuts2==14 the
nuts3 variables takes on values
## [1] 1401 1402 1403 1404 1405 1406 1407 1408 1409 1410 1411 1412 1413 1414 1415In the swapped data set there are however many more values for
nuts3 now which are not coherent with nuts1==1
and nuts2==14
## [1] 1110 1213 1306 1313 1401 1402 1403 1404 1405 1406 1407 1408 1409 1410 1411 1412 1413 1414 1415 1504 1513 2111 2212 2302 2312 2314 2404 2410 2412 2505 2510 2511 3105
## [34] 3113 3201 3205 3211 3307 3313 3314 3404 3406 3407 3408Using the parameter carry_along one can define certain
variables which are additionally swapped but do not interfere with the
risk calculation, sampling and procedure of finding a donor.
dat_swapped2 <- recordSwap(data = copy(dat),
hid = hid,
hierarchy = hierarchy,
similar = similar,
risk_variables = risk_variables,
swaprate = 0.05,
carry_along = c("nuts3","lau2"), # <- swap nuts3 and lau2 variable as well
seed=1234L)## Recordswapping was successful!
geoVars <- c("nuts1", "nuts2", "nuts3")
dat_geo <- dat[!duplicated(hid),..geoVars]
setorderv(dat_geo,geoVars)
dat_geo_swapped <- dat_swapped2[!duplicated(hid),..geoVars]
setorderv(dat_geo_swapped,geoVars)
# check if value combinations of swapped and original data are the same
all.equal(dat_geo,dat_geo_swapped)## [1] TRUEBoth the original and swapped data set have the same value
combinations for nuts1, nuts2 and
nuts3. Setting this parameter did, however, not interfere
with the swapping procedure
dat_compare2 <- merge(dat[,.(paste(nuts1[1],nuts2[1])),by=hid],
dat_swapped[,.(paste(nuts1[1],nuts2[1])),by=hid],by="hid")
# check if same hid were swapped in both cases
all.equal(dat_compare2[order(hid),.(hid)],
dat_compare[order(hid),.(hid)])## [1] TRUEUsing the same idea one can set return_swapped_id = TRUE
to return the hid with which the records were swapped
with.
dat_swapped3 <- recordSwap(data = copy(dat),
hid = hid,
hierarchy = hierarchy,
similar = similar,
risk_variables = risk_variables,
swaprate = 0.05,
carry_along = "nuts3",
return_swapped_id = TRUE,
seed=1234L)## Recordswapping was successful!The output now has an additional column named
hid_swapped, which contains the household ID with which a
household was swapped with.
Number of swapped hids
dat_swapped3[!duplicated(hid),.N,by=.(id_swapped = hid!=hid_swapped)]## id_swapped N
## 1: TRUE 500
## 2: FALSE 9500Supplying your own risk values
Instead of using k_anonymity and
risk_variables for the calculation of a number of swaps,
custom risk can be supplied. For custom risk for households can be used
parameters risk and then the parameter
risk_threshold is used to determine high-risk households.
High-risk households are always swapped, and households with risk lower
than the threshold are also used as donor households. To ensure that the
household is not swapped, its risk must be set to 0.
hid <- "hid"
similar <- list(c("hsize"))
hier <- c("nuts1","nuts2","nuts3")
risk_threshold <- 0.9
# set risk matrix with low risk for everybody
risk <- matrix(
data = rep(0.0001,3*nrow(dat)),
ncol = 3,
dimnames = list(1:nrow(dat),
hier))
# for example, assign random people high risk value
set.seed(1234L)
risk[sample(1:(length(hier)*nrow(dat)),size = 50)] <- 99 # risk value
dat_swapped4 <- recordSwap(data = copy(dat),
hid = hid,
hierarchy = hier,
similar,
risk = risk,
risk_threshold = risk_threshold,
swaprate = 0,
return_swapped_id = TRUE,
seed = 1234L)## risk was adjusted in order to give each household member the maximum household risk value## Recordswapping was successful!Information loss
With the function infoLoss() one can calculate various
information loss measures over a pre defined frequency table. This
frequency table is defined by the parameter table_vars,
which accepts column names of the original and swapped micro data. The
frequency table is internally constructed using both the original and
swapped micro data. Afterwards, various information loss measures are
estimated over each of the table cells.
# calculate information loss for frequecy table nuts2 x national
table_vars <- c("nuts2","national")
iloss <- infoLoss(data=dat, data_swapped = dat_swapped3,
table_vars = table_vars)
iloss$measures## what absD abssqrtD relabsD
## 1: Min 0.000000 0.00000000 0.000000000
## 2: 10% 0.000000 0.00000000 0.000000000
## 3: 20% 0.000000 0.00000000 0.000000000
## 4: 30% 1.000000 0.02275320 0.002072981
## 5: 40% 2.000000 0.04496512 0.004035576
## 6: Mean 3.473684 0.08023104 0.007423091
## 7: Median 3.000000 0.07005226 0.006564551
## 8: 60% 4.000000 0.09223914 0.008472307
## 9: 70% 5.000000 0.11484568 0.010517821
## 10: 80% 7.000000 0.15666865 0.014084507
## 11: 90% 8.000000 0.18272876 0.016724520
## 12: 95% 9.300000 0.21856234 0.020476550
## 13: 99% 11.060000 0.26366336 0.025462325
## 14: Max 12.000000 0.27945378 0.026373626Per default the absolute deviation (\(abs(x,y)\)), relative absolute deviation
(\(r\_abs(x,y)\)), and absolute
deviaion of square roots (\(abs\_sqr(x,y)\)) is calculated between the
table cells x and y, see also parameter metric.
\[ abs(x,y) = |x-y| \]
\[ r\_abs(x,y) = \frac{|x-y|}{x} \]
\[ abs\_sqr(x,y) = |\sqrt{x}-\sqrt{y}| \]
It is also possible to supply a custom information loss metric by
using parameter custom_meric
# define squared distance as custom metric
squareD <- function(x,y){
(x-y)^2
}
iloss <- infoLoss(data=dat, data_swapped = dat_swapped3,
table_vars = c("nuts2","national"),
custom_metric = list(squareD=squareD))
iloss$measures # includes custom loss as well## what absD abssqrtD relabsD squareD
## 1: Min 0.000000 0.00000000 0.000000000 0.00000
## 2: 10% 0.000000 0.00000000 0.000000000 0.00000
## 3: 20% 0.000000 0.00000000 0.000000000 0.00000
## 4: 30% 1.000000 0.02275320 0.002072981 1.00000
## 5: 40% 2.000000 0.04496512 0.004035576 4.00000
## 6: Mean 3.473684 0.08023104 0.007423091 22.69474
## 7: Median 3.000000 0.07005226 0.006564551 9.00000
## 8: 60% 4.000000 0.09223914 0.008472307 16.00000
## 9: 70% 5.000000 0.11484568 0.010517821 25.00000
## 10: 80% 7.000000 0.15666865 0.014084507 49.00000
## 11: 90% 8.000000 0.18272876 0.016724520 64.00000
## 12: 95% 9.300000 0.21856234 0.020476550 86.70000
## 13: 99% 11.060000 0.26366336 0.025462325 122.38000
## 14: Max 12.000000 0.27945378 0.026373626 144.00000sdcMicro Objects
The function recordSwap() can be called using the micro
data directly, as seen above, or with an sdcMicro-Object. Parameters for
the swapping routine can be passed to the options-slot when creating the
sdcMicro-Object.
# define paramters
hierarchy <- c("nuts1","nuts2")
risk_variables <- c("hincome","ageGroup","gender")
k_anonymity <- 3
swaprate <- .05
hid <- "hid"
similar <- "hsize"
# create sdcMicro object with parameters for recordSwap()
data_sdc <- createSdcObj(dat,hhId = hid,
keyVars=risk_variables,
options = list(k_anonymity = k_anonymity,
swaprate = swaprate,
similar = similar,
hierarchy = hierarchy))
dat_swapped_sdc <- recordSwap(data = data_sdc,
return_swapped_id = TRUE)## Recordswapping was successful!
dat_swapped_sdc[!duplicated(hid),.N,by=.(id_swapped = hid!=hid_swapped)]## id_swapped N
## 1: FALSE 9500
## 2: TRUE 500